© 2023 yanghn. All rights reserved. Powered by Obsidian
7.2 使用块的网络(VGG)
要点
- VGG 利用模块化的思想,使用可重复的卷积块来构建卷积神经网络
- VGG 块每用一次,图像大小减少 1/2,相应的通道数就要翻倍
- 论文用的是 224x224 的图片,这也是 ImageNet 非官方标准
- 参数的大头在卷积层后的第一个全连接层(所有输出通道的像素展平*4096个参数)
AlexNet 比 LeNet 好用的原因是更大,更深的网络来实现:
- 更多的全连接层(太贵,训练成本太高)
- 更多卷积层(可以用)
使用块的想法首先出现在牛津大学的视觉几何组(visual geometry group)的_VGG 网络_中。通过将几个卷积层组合成块,构成 VGG
1. VGG 块
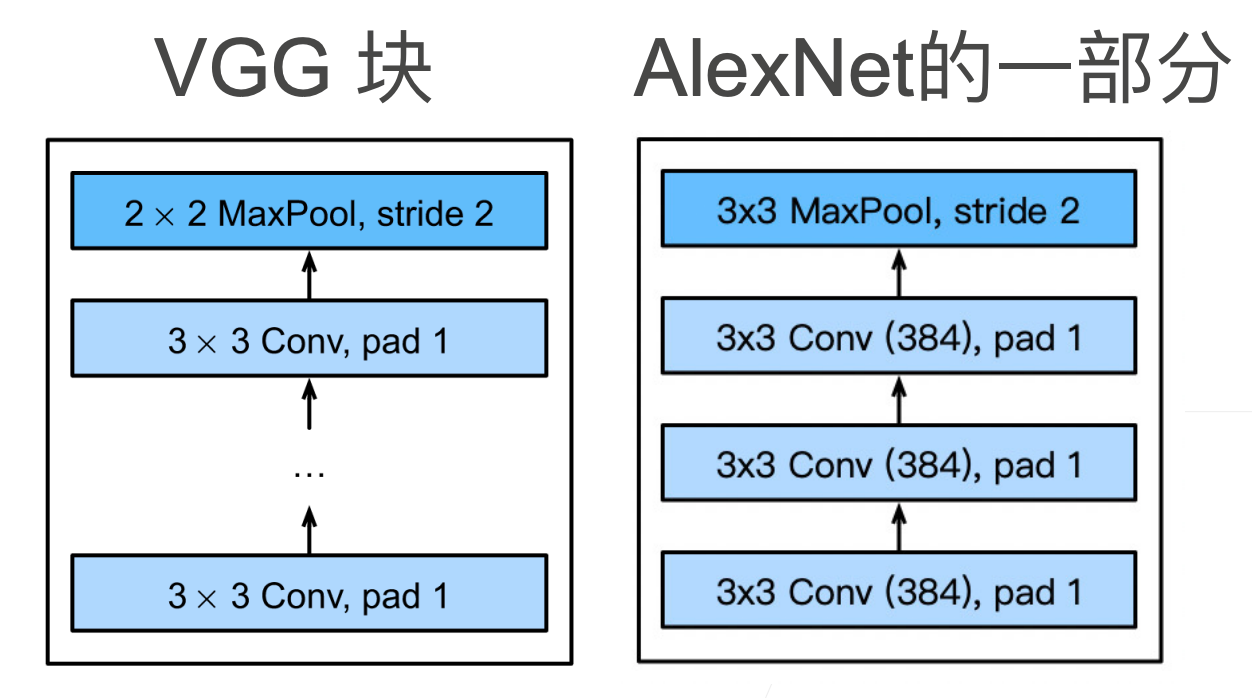
思考: 为什么用 3x3 而不是 5x5 的卷积核?
模型更深,窗口小一点效果更好
import torch
from torch import nn
from d2l import torch as d2l
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels,
kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels # 块内的卷积层通道大小一致
layers.append(nn.MaxPool2d(kernel_size=2,stride=2))
return nn.Sequential(*layers)
net = vgg_block(3,256,384)
X = torch.randn(1, 256, 224, 224)
for layer in net:
X=layer(X)
print(layer.__class__.__name__,'output shape:\t',X.shape)
Conv2d output shape: torch.Size([1, 384, 224, 224])
ReLU output shape: torch.Size([1, 384, 224, 224])
Conv2d output shape: torch.Size([1, 384, 224, 224])
ReLU output shape: torch.Size([1, 384, 224, 224])
Conv2d output shape: torch.Size([1, 384, 224, 224])
ReLU output shape: torch.Size([1, 384, 224, 224])
MaxPool2d output shape: torch.Size([1, 384, 112, 112])
2. VGG 架构
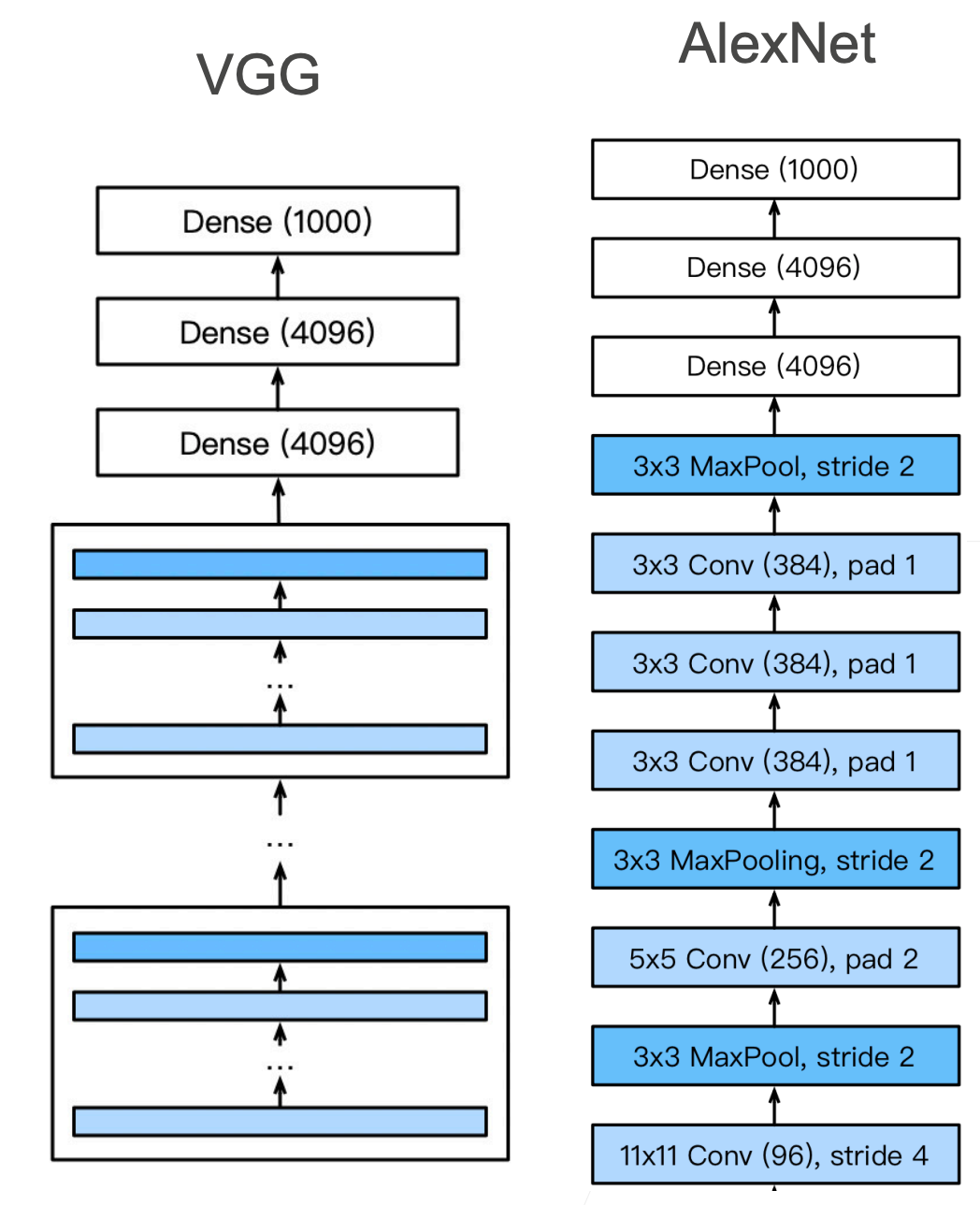
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512)) # 1表示一个 VGG 块中 3x3 卷积层的个数,64 表示输出通道数
def vgg(conv_arch):
conv_blks = []
in_channels = 1
# 卷积层部分
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
# 全连接层部分
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10))
net = vgg(conv_arch)
上面也是原始论文中 VGG-11 的架构,原始VGG网络有5个卷积块(因为 224 除以 5 次 2 后等于 7,无法继续除以 2)
X = torch.randn(size=(1, 1, 224, 224))
for blk in net:
X = blk(X)
print(blk.__class__.__name__,'output shape:\t',X.shape)
Sequential output shape: torch.Size([1, 64, 112, 112])
Sequential output shape: torch.Size([1, 128, 56, 56])
Sequential output shape: torch.Size([1, 256, 28, 28])
Sequential output shape: torch.Size([1, 512, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
Flatten output shape: torch.Size([1, 25088])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 10])
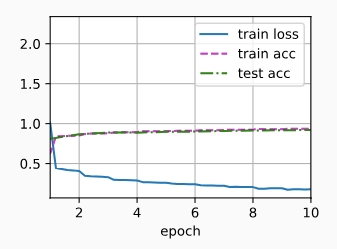
训练 VGG 网络
ratio = 4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)
# 超参数设定
lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
loss 0.178, train acc 0.935, test acc 0.920
2463.7 examples/sec on cuda:0
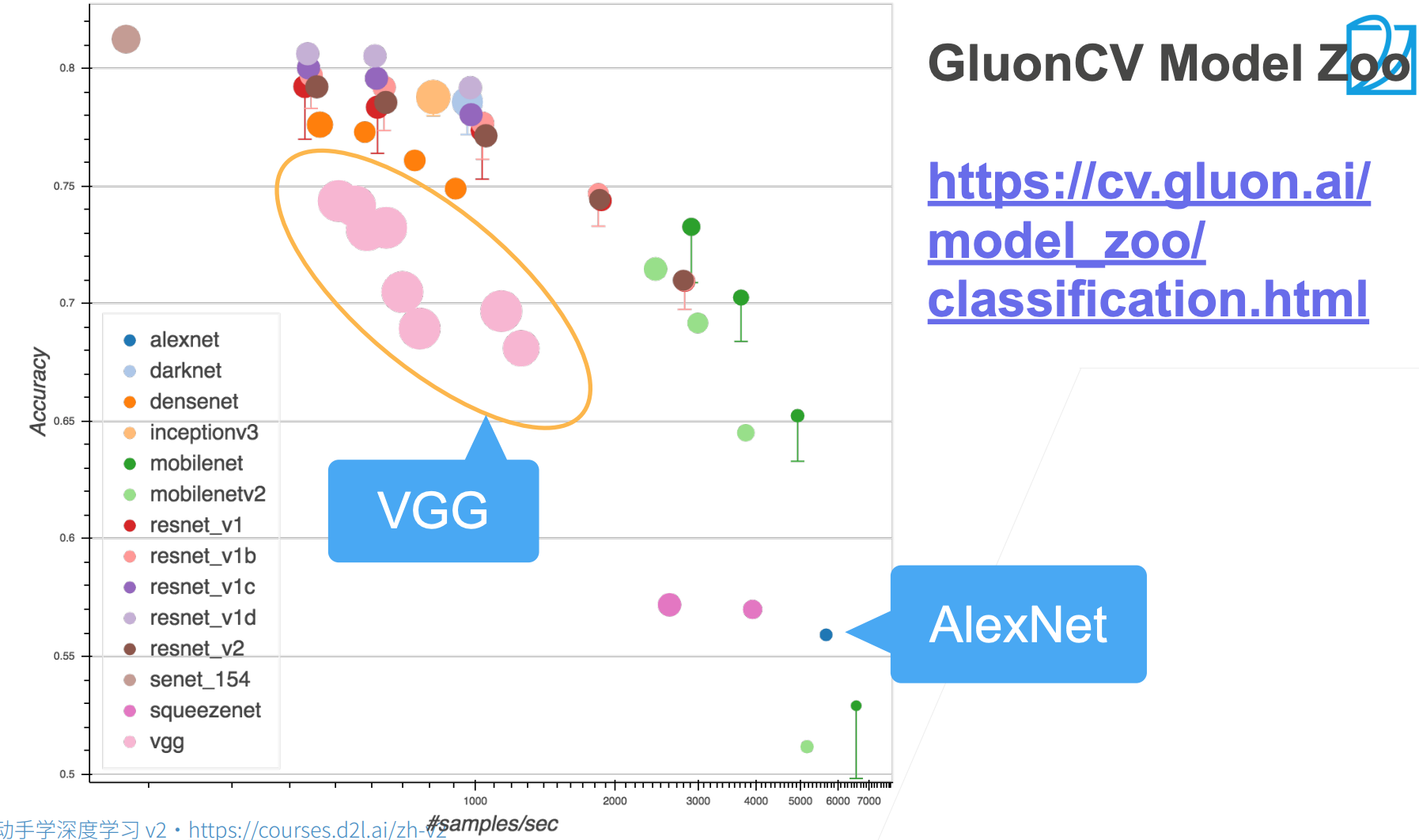
上图中,圆圈里下方的竖线表示论文的精度,加上一些 trick、调参之后可以提升精度